Architecture
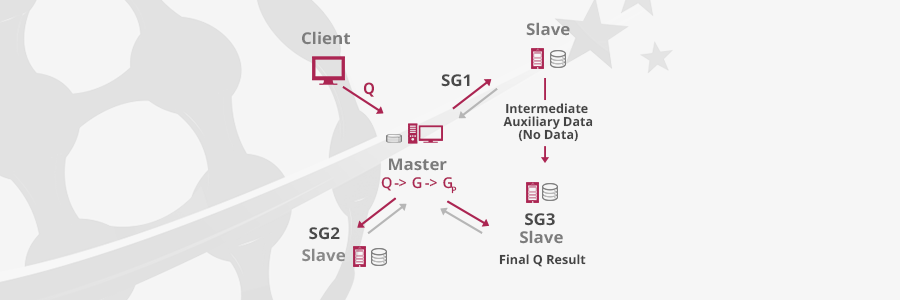
Figure 1: DREAM’s architecture (Q= SPARQL Query; G = Q’s Query Graph; GP = {SG1, SG2, SG2} = G’s Graph Plan).
DREAM adopts a master-slave architecture as shown in Figure 1. In principle, each slave machine can encompass any centralized RDF store, including relational-based and graph-based stores, among others. Accordingly, DREAM offers a general purpose scheme, whereby it does not impose any specific data model and can be easily tailored to incorporate any desired storage layout. Assuming an input RDF dataset, D , each slave machine stores D unsliced. A client can submit a SPARQL query,Q , to the master machine which, in turn, transforms it into a graph, G , and feeds it to DREAM’s query planner. The query planner of DREAM partitions G into a set of sub-graphs, GP = {SG1, ..., SGM}, where M is less than or equal to the number of slave machines. During execution, slave machines exchange intermediate auxiliary data, join intermediate data and produce Q’s final result.
Since D is maintained as a whole at each machine, DREAM does not shuffle intermediate data whatsoever and only communicates identifiers of triples (i.e., auxiliary data). Besides, as slave machines can include any centralized RDF store (e.g., RDF-3X [1]), each sub-graph executed at each machine can be further optimized using the store’s query optimizer (if any). Lastly, since any query graph, G, can be partitioned into many sub-graphs or kept as is, DREAM can run in a distributed or a centralized manner. This is dictated by the query planner which generates a graph plan, GP (i.e., the set of partitioned sub-graphs), for each G that maximizes parallelism and minimizes network traffic.
[1] Thomas Neumann and Gerhard Weikum. The RDF-3x engine for scalable management of RDF data. The VLDB Journal, 19(1), 2010.